


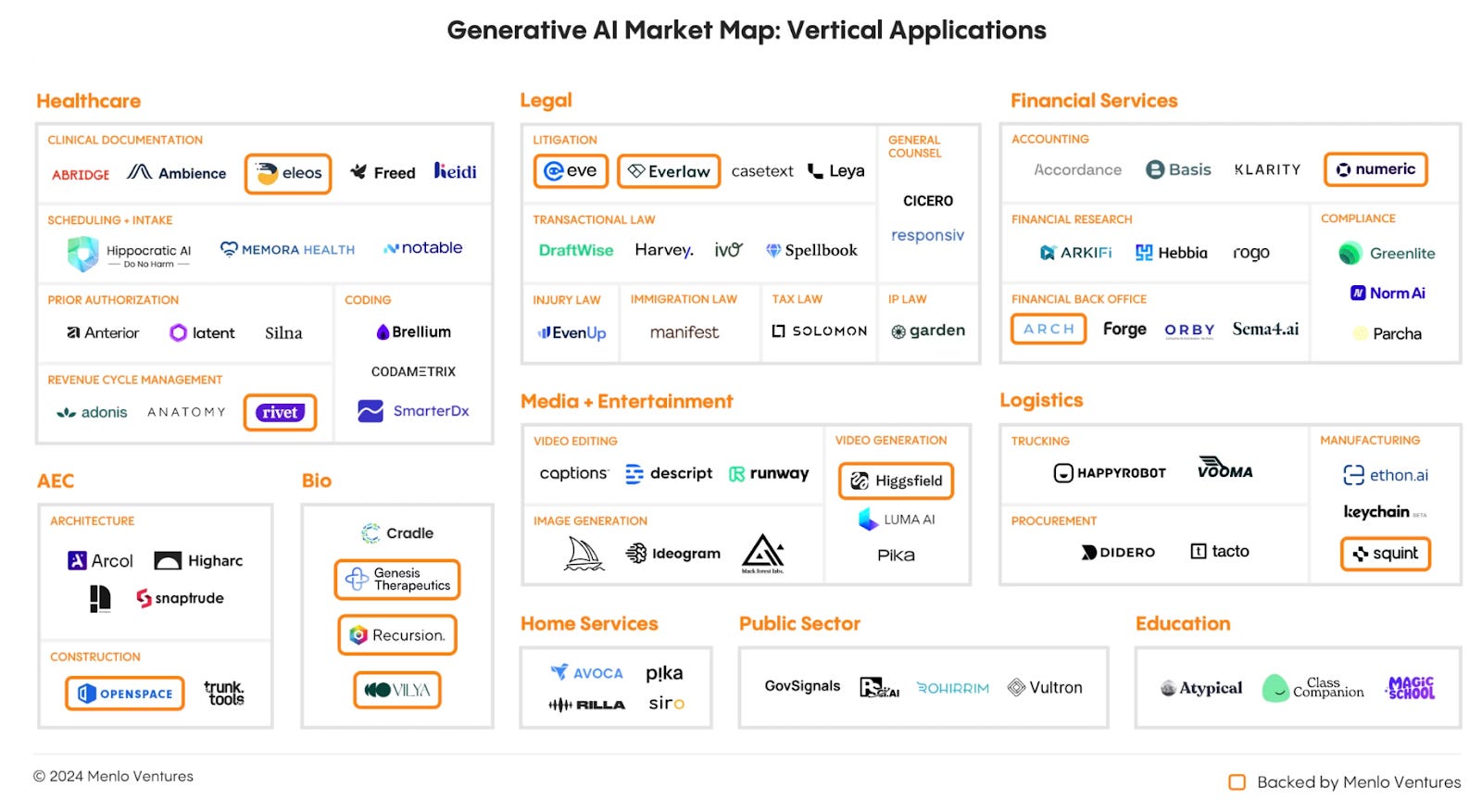
For your holiday reading, here are some thoughts on current trends in Generative AI. Many thanks to three people who contributed ideas and suggestions: Meryem Arik, Nick King, and Rajiv Shah.
Enterprise Adoption
Where are we in GenAI adoption?
Many published surveys and reports about GenAI come from people with an axe to grind. Is McKinsey neutral about GenAI? GTFO. GenAI is the biggest boon for consultants since Y2K; they’re all pushing FOMO like an evangelist pushes Jesus.
Menlo Ventures has an axe to grind, but this report is good.
I don’t have an axe to grind; I’m retired and don’t own any axes. So here’s an observation based on a sample of one. Recently, I spoke with a former colleague; she is now the data science team leader for a multi-billion dollar global CPG. We chatted about the usual stuff – where is so-and-so working now, how do you like working for a big company, that sort of thing.
She mentioned that she plans to triple the size of her team.
“Really!” said I. “How much of your work is GenAI?”
“About eighty percent,” she replied.
“You’re kidding.”
“Nope. We’re all in.”
Eighty fucking percent. It’s a new frontier, people. Saddle up.

Declining Inference Costs
AI pessimists love to cite the cost of inference. “OpenAI has colossal revenue growth, but there’s no way they can make money! Did you know that an AWS g4dn.12xlarge on-demand instance with four GPUs costs four whole dollars an hour? Do the math!”
Yes, inference is relatively expensive for large models that require accelerated hardware. Inference is costly for all large models, not just those used for GenAI applications. High inference costs may limit GenAI adoption to the highest-value use cases.
But here’s a red pill: inference costs are declining and will continue to do so. Key factors driving this trend include:
Wider use of hardware load balancing and autoscaling
New serving capabilities: multi-model serving, dynamic batching, and GPU sharding
Smart model optimization, including pruning and quantization
Improved development: more efficient prompt engineering and smart caching
Most technologies are relatively expensive when first introduced, but costs decline with scale and experience. Steam locomotives, mechanical harvesters, automobiles, airplanes, computers, cell phones, and solar panels follow the same pattern.
Increased use means economies of scale and lower unit production costs. With experience, producers develop ways to make things better, cheaper, and faster; users develop skills, identify best practices, and establish standards.
Investors in GenAI believe that costs will decline enough for GenAI applications to make money.
AI Agents
If you believe Google Trends, AI Agents have legs. The concept is intriguing. I advise caution. In 1995, Gartner promised us “autonomous agents” in data warehouses that would change everything. What did we get? Stored procedures and table functions.
Advocates tout AI agents for customer service. AI agents for customer service suck, and companies that deploy them hate their customers.
Vendor Focus
OpenAI integrates vertically across three distinctly different businesses:
LLM Development (the GPT and DALL-E series, Whisper, etc.)
LLM Hosting (the OpenAI API)
GenAI Applications (ChatGPT)
In retrospect, vertical integration was a smart choice for OpenAI. Who would have noticed if OpenAI had published the GPT models without ChatGPT? Nobody outside of the nerd community. ChatGPT delivered the power of GenAI to a mass audience; OpenAI had to build that for maximum impact.
No other vendor will copy that business model, and it may not be sustainable for OpenAI. Developing an LLM from scratch requires distinct skills, tooling, and resources. Hosting an LLM in production at scale requires entirely different capabilities. You need a third set of distinct skills to build GenAI applications.
Note: A reader points out that Anthropic integrates vertically across all three businesses, so my statement that “no other vendor will copy that business model” is inaccurate. That's fair enough. I meant “no new entrant...”
To compete effectively, vendors must focus on one of the three businesses: development, hosting, or applications. This is not a prediction; it is happening right now.
Development: LLM developers want to distribute their models through as many channels as possible. Llama is one of the most widely used LLMs today; Meta doesn’t host an API but relies exclusively on partners for distribution. Cohere and Mistral's models are available as native services on AWS, Azure, GCP, IBM, and other platforms. Anthropic offers its Claude models through AWS and GCP; Anthropic’s API is AWS behind the scenes.
Hosting: Cloud platforms compete to provide their customers with the broadest selection of models. AWS Titan isn’t a competitive LLM, but AWS offers a comprehensive library of models, including Gemma and OpenGPT, in Bedrock, JumpStart, and the Marketplace. In other words, AWS focuses on its core hosting and infrastructure skills. Microsoft knows that an exclusive reliance on OpenAI isn’t a winning strategy; Azure offers native services for Cohere, Llama, Mistral, and others. Google initially tried to shove Gemini on every GCP customer, but now, it provides a broad selection, including Claude, Llama, Mistral, and others.
Applications: In GenAI, like every other technology, the money is at the top of the stack. Google embeds Gemini in search, and Microsoft embeds LLMs in everything, including the kitchen sink. Many LLM vendors offer light-duty chat apps for exploration, but custom home-grown applications are now the rule. In build vs. buy assessments, the strongest case for “build” is in the last mile to the end user.
Developing new LLMs strikes me as the least attractive business. Well-funded existing players will continue to expand and enhance their product lines, but new entrants will struggle for mindshare. Large language models are ubiquitous and free. Hugging Face has collected them diligently for eight years; from a commercial perspective, they might as well collect rocks.
There’s plenty of money in hosting and infrastructure, but good luck competing with AWS, Azure, and GCP.
The GenAI opportunity is in applications. Custom applications are the norm right now, but that won’t last. It may take a year or two for startups currently in seed to develop stable products, but off-the-shelf applications will soon displace home-grown ones. The startups that succeed will position themselves as vertical and role-based assistants, not geeky GenAI shit. Execs with money want solutions to business problems, not “better prompt engineering.”
Model Gravity
Remember that leaked Google memo? “We have no moat and neither does OpenAI.”
It’s not true. You are the moat: you and your applications.
You lead a team of AI developers. Your CEO wants your team to build a mission-critical GenAI application, which she wants yesterday. Your first problem: choose a large language model to support your application. What model will you use?
You check Hugging Face and discover almost a million models on that platform. The Hugging Face leaderboard says that today’s leader is MaziyarPanahi/calme-3.2-instruct-78b.
Oops, that’s experimental.
Tomorrow’s leader will be something else.
You think Stanford people are smart. You check the Center for Research on Foundation Models. There, you discover eleven leaderboards with different leaders. You wonder if there is a leaderboard of leaderboards.
I can beat this dead horse all day, but here’s the point: the explosion of models makes model selection for GenAI applications a significant challenge. There are many competing benchmarks, and the assessments aren’t stable. Even if a large language model gets the best score on a general-purpose evaluation, that does not mean it is the best model for your application.
You can’t test every model, either. You might be able to test a few, but how will you decide which ones to test?
The short answer: you won’t. The model selection problem is so complex that no team with a deadline can afford to optimize it. You will choose a model based on heuristics, a fancy-ass word for “rules of thumb.”
The first rule of thumb is that small differences in model accuracy have little or no business impact. Your clients won’t care that you chose the LLM with the best benchmark. If you deliver an application that works, you’re a hero; otherwise, you’re fired.
The second rule of thumb is that every model has a learning curve. Every model handles prompts in distinct ways. Developers who work with a model develop a detailed understanding of a model’s syntax and semantics.
In short, when a developer team delivers a successful application with a large language model, that model is automatically on the shortlist for the next project. For every additional project a team completes with a model, the probability that they will use that model for the next project approaches certainty.
Call it the Law of Model Gravity.
Suppose your team builds a dozen applications with Llama 2 because it tops the HELM leaderboard today. Mistral pushes an update tomorrow, and the new version tops the updated leaderboard. Will you rip out your existing apps and rebuild them with Mistral? No, you won’t.
Now, look ahead a few years when there will be a hundred GenAI apps in production, not a dozen. Swapping LLMs will be even harder than it is now.
You and your applications are the moat for LLM developers. That’s why every LLM developer wants you to start building those production apps right now. It’s a land grab for tech; your use cases are the land.
AI Regulation
If history is a guide, legislators will approach regulation with good intentions and create a complicated mess that locks in the biggest players, creates more work for lawyers and other grifters, and does little to protect the public.
The EU rushed into AI regulations because the EU doesn’t know how to build anything else.
Self-Hosting
When you build a GenAI application, you have three options for the supporting LLM:
Connect to a managed service, such as Amazon Bedrock, Azure OpenAI Service, or Google AI.
Use an LLM in a model garden, such as Amazon SageMaker JumpStart, Hugging Face, or Orq.ai.
Host a private LLM with tools like TitanML, Triton Inference Server, or Ray-Serve.
Is there a trend towards self-hosting? Google Gemini thinks so, but the supporting citations are vendor pitches, so we should take that with a dose of salt.

Choosing the best option is a build-or-buy question, and there’s a rubric. Ask yourself three questions:
Does your application have unique requirements?
Will your application have a strategic impact on your business?
Do you have the will and the skill to build, manage, monitor, and maintain an inference server?
If you can answer “yes” to all three questions, self-hosting is a good option for you to consider. Otherwise, use a managed service or a model garden.
Forget about saving money. Building your own shit is always more expensive when you consider the cost of human resources. Yes, the cost of prompts to a managed service add up, but you will need a massive volume to cover the fixed overhead of self-hosting.
Requirements that will drive you to consider self-hosting include:
Security concerns about cloud-based remote APIs.
Policy needs, including more control over guardrails and other LLM “wrappers.”
Need for very low response latency. Many managed LLM services lack an SLA, or the SLA is not acceptable for your needs.
Self-hosting may be the only option if you must use a privately developed or tuned LLM.
You worked with the client to define requirements for an application and identified unique requirements such as those cited above.
Now, determine whether this application has a strategic impact on the business. Why do that? If it doesn’t, you will return to the client and get them to compromise because this weak-ass application doesn’t warrant a custom build.
Diplomatically, of course.
If your requirements are truly unique and this application is mission-critical, assess your team’s skills. Do you have what it takes to manage an inference engine at scale, with high availability and an aggressive SLA?
Be honest. Either you do, or you don’t. You don’t want to discover a talent gap six months from now when your clients start getting antsy.
In my experience, some organizations consistently excel at managing IT infrastructure. Others consistently suck. You already know whether your business falls into the former or the latter category. Some companies, like Capital One and Verizon, have a history of IT excellence and successful project delivery. Others, who I will not name, have a history of IT ineptitude; they should run away from self-hosting.
Today, organizations in regulated industries are most likely to self-host. They need more flexibility in the policy layer than managed services provide, and keeping leadership out of jail is a strong incentive.
Artificial General Intelligence
Me, when anyone mentions AGI:

Tom, I’m curious if these articles are as fun to write as they are to read?
AI agents for customer service suck, and companies that deploy them hate their customers.
That goes both ways 😁
Great article, as always