A Short History of AutoML: Part Two
Starbucks and Macros


It’s 1998. You work for a big company, and you want to predict something with data. You studied Statistics in grad school, and your job title is “Analyst.”
You use SAS on a Solaris machine. Most of your work is Base SAS for data wrangling. You develop models with SAS/STAT and a few other packages, including CART. You write a lot of SAS Macros because SAS still doesn’t have a built-in grid search for GLM.
SAS launched Version 6 in 1985. The SAS rep says that Version 7.0 is “right around the corner.” She hands you a list of new features: Output Delivery System, Long Variable Names, SAS/Connect, Dynamic Libnames, and Indexing Enhancements.
You wonder who wants that stuff. When will SAS have a built-in grid search? She promises to get back to you.
You're looking for a better alternative to stepwise regression. SAS has a Ridge option in PROC REG for Tikhonov Regularization. That method doesn’t knock out weak variables; you get a more accurate model that is hard to interpret. If you’ve ever tried to explain anything to Marketing, you understand why that’s a problem.
A Stanford professor published a paper two years ago proposing a new technique called Lasso. Seems promising. SAS doesn’t support it natively, so you wrote a SAS Macro for it.
You ask the rep when SAS will support Lasso. She promises to get back to you.
You work with thirty-four data sources. There are the Oracle Data Warehouse, the SAP Business Warehouse, and the Siebel data store. The mainframe has a slew of MVS datasets that they haven’t migrated yet, and likely never will. Marketing has a database at Acxiom, the Nielsen and IRI data, and a bunch of outside agencies that send data on floppies. Then there are the departmental databases in Microsoft Access and SQL Server, the subsidiary running on Informix, and the other subsidiary with EBCDIC files on AS/400s.
Consultants think this is horrible. You think it’s fine. You know where to find everything, and SAS works with all the databases.
Your new VP of IT has a vision. He wants to build a Big, Beautiful Data Warehouse to replace all the data silos in the organization. He’s ex-Teradata, and guess what vendor he wants for the BBDW.
You attend a presentation by Teradata. Sure enough, they tell the beer and diapers story. You wonder how long they will keep fucking that chicken.
At conferences, you hear a lot of talk about data mining. You laugh; your professors warned against data dredging, data hacking, data snooping, and fishing expeditions. You don’t mine insight; you manufacture it with designed experiments, control groups, and split tests. That’s how Capital One disrupted the credit card industry.
Retrospective data analysis sometimes produces interesting correlations. Some of those correlations are useful. Most are spurious.
Integral Solutions is a tiny English company that sells Clementine, a “data mining workbench.” You like to keep track of new products, so you invite them to make a presentation.
Clementine has a handful of built-in operators for data prep, including filtering, merging, and aggregation. For modeling, there are the usual suspects: decision trees, linear models, neural networks, apriori association rules for your beer and diapers work, and k-means clustering. There are also esoteric things, such as C5.0 trees, rule induction, and Kohonen Maps.
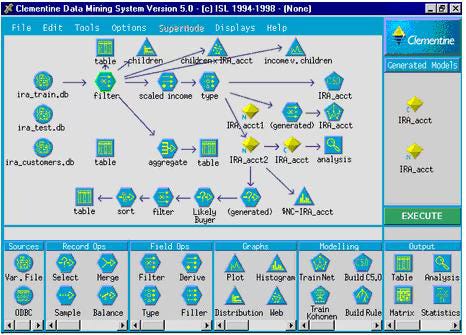
Everything in the tool is drag-and-drop, but nothing is automated. The user must specify and configure every operation. Clementine targets users who are smart enough to decide between C5.0 and Kohonen Maps, but too dumb to learn how to code. It’s a cafeteria where you serve yourself from a limited menu.
You ask the rep to explain what people do with Kohonen Maps. The rep promises to get back to you.
Sure enough, your SAS Account Executive hears about the ISL pitch. She calls to gush about SAS Enterprise Miner, now in experimental release. You agree to a meeting.
She has screenshots of SAS Enterprise Miner. It looks like Clementine. Oh well, nobody expects SAS to innovate.
You can use Enterprise Miner even if you don’t know how to program in SAS, the representative says. Why does she think that’s a selling point? You already know how to program in SAS, and so does everyone in the room. You don’t hire people if they don’t know SAS.
She ticks off Enterprise Miner’s features. Pretty much the same as Clementine: decision trees, linear models, neural networks, association rules, and clustering, plus some data prep operators.

Once again, nothing is automated. The tool only works with SAS datasets. If the users don’t know SAS, they will need a team of SAS data butlers to support them. It’s like those Horn and Hardart Automats; simple for the buyer, but there’s an army of cooks and bottle-washers behind the wall.
You ask whether SAS Enterprise Miner supports Kohonen Maps. The rep looks sad. No, this release of Enterprise Miner does not include Kohonen Maps. You pretend to be sad, too, and ask her to call when it does.
You attend a presentation by a guy named Drew, who leads a startup called MarketSwitch. He babbles about how his company’s tool uses “Russian rocket science” to optimize marketing. The Soviets were really good at marketing – we know this because shoppers always lined up outside the grocery stores.

Every time he mentions “Russian rocket science,” he gestures towards his co-presenter, a guy named Yuri. You check the bios in the back of the package. Yuri attended the Moscow Aviation Academy, so he really is a Russian rocket scientist. You wonder if he contributed to Chernobyl.
MarketSwitch uses linear programming for offer optimization. Seems like overkill. In your company, Marketing managers sit around a table every month and fight over priorities. Usually, they end up sending every offer to every eligible customer, and nobody cares if some people get twenty offers. Bulk mail is cheap, and Marketing cares more about volume than ROI.
The MarketSwitch engine needs a response model for each offer. That’s a lot of response models to crank out. Not to worry! Drew explains that MarketSwitch has an automated modeling tool “So you can fire all your SAS programmers.”
You thank Drew and Yuri for their time and laugh at them when they’re gone.
Another tiny company called Unica has a booth at a Marketing convention. They’re pushing software called Pattern Recognition Workbench.
You agree to a free trial. PRW is easy to install and well-designed. The product automates experiments over several machine learning algorithms, including neural networks. There’s a built-in spreadsheet for manual feature engineering. It’s a little better than Clementine and Enterprise Miner, and it’s easy to use.
When you test the tool with data, neural networks never win the horse race. They are still overkill for your use cases, and nobody has figured out how to optimize an ANN while we’re young. So it’s really just a tool to test linear models versus decision trees, and that doesn’t save time.
PRW comes with a book called Solving Pattern Recognition Problems, which you skim. Too many words, and bad positioning. Nobody with a budget cares about “patterns.” Increase my sales, lower my costs, keep me out of jail, or get out of my office.
“You wonder if he contributed to Chernobyl” got me good. Great series!